.avif)
.avif)
.svg)

As AI advancement has exploded, the best description of the pace of change has been “blink and you’ll miss it.” New innovations are emerging practically on a weekly basis.
Building effective AI solutions in this environment–and knowing which technological bets to make and which ones to pass on–takes both technical expertise and strategic flexibility. At Zowie, we've developed an AI architecture that not only solves today's customer service challenges but can also adapt as the technology keeps evolving.
Our approach: customer-centered problem solving
Zowie is operating in a space where yesterday's cutting-edge approach becomes today's baseline. You simply can't afford to stand still–yet you need to build technology that actually accomplishes the tasks it’s designed to do.
At Zowie, we've built our AI Agent architecture on a foundation of flexibility. Our philosophy is to make decisive moves quickly with flexibility built into the DNA of our systems, rather than paralyzing ourselves waiting for the "perfect" information that will never come.
The cornerstone of our approach is straightforward yet powerful: deeply understand the problems our customers face before writing a single line of code. We don’t chase technical novelty for its own sake. Instead, we immerse ourselves in our customers' challenges, identify their friction points, and craft solutions purpose-built to solve those specific problems.
This customer-first approach drives every architectural decision we make. At the same time, we've focused on creating architecture that’s adaptable and future-proofed for new innovations in AI.
Our AI architecture: dynamic, adaptive, and intelligent

We’ve honed our AI Agent architecture over time, adding and extending our capabilities so that Zowie powers real change and growth for our customers.
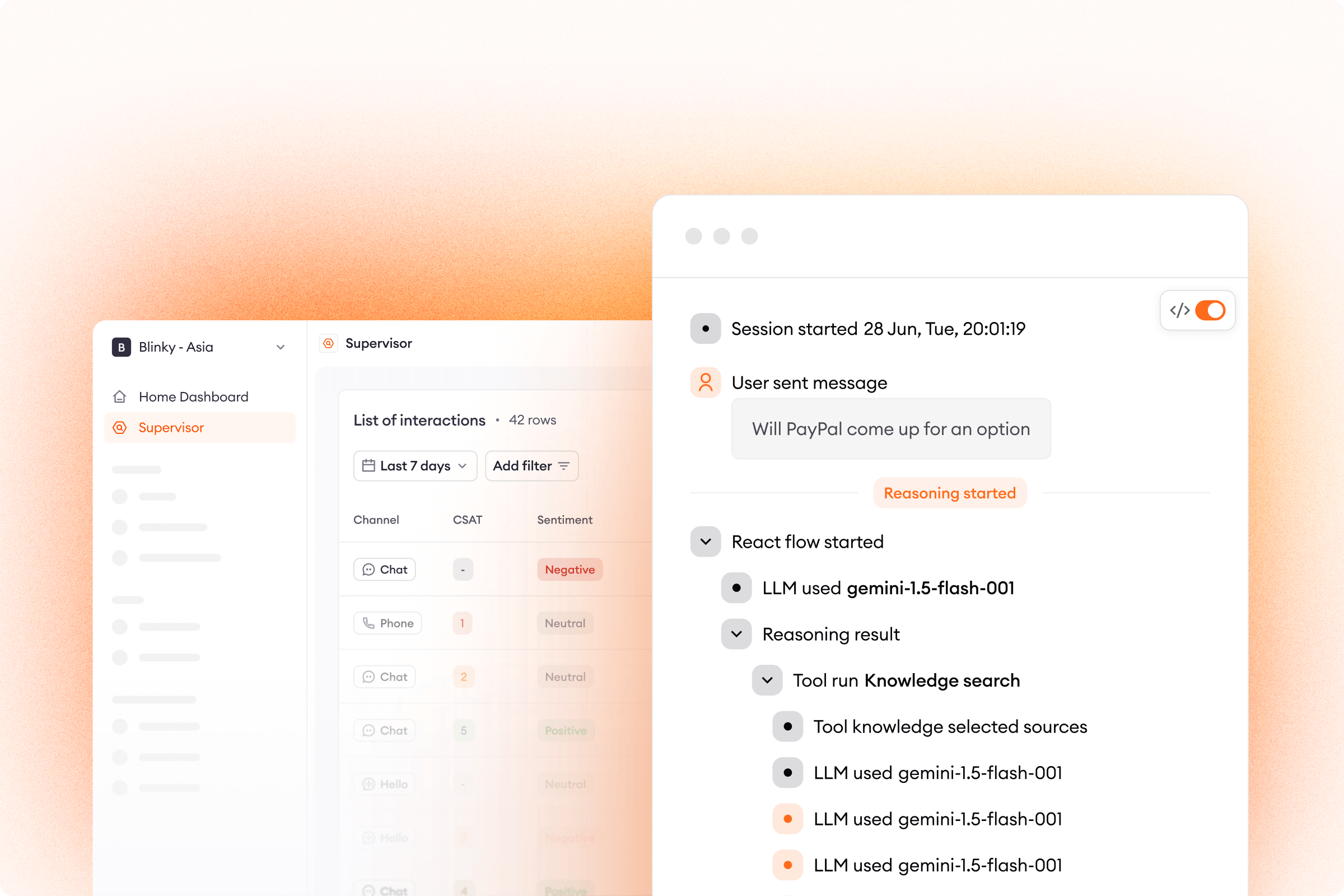
When our customers receive a message from an end user, the query doesn’t follow a rigid, scripted path—it flows through an intelligent ecosystem designed to deliver the fastest, most accurate resolution possible. Here's how our AI Agent system processes an inquiry:
1. Entry and initial assessment
Every end user interaction begins with a message arriving through one of our supported channels. Immediately, our AI Agent makes a critical first decision: can we answer this directly based on existing context?
If enough context exists—perhaps from previous interactions or account history—our AI Agent gives an immediate answer without unnecessary processing. This "fast path" significantly reduces response times for straightforward, contextually clear inquiries.
2. Intent recognition and routing
For queries requiring deeper understanding, our three-step intent recognition system activates. This system doesn't just categorize messages—it truly understands them, determining whether:
- The query matches a specific process that should be handled by the Decision Engine
- The question is general and requires our Reasoning Engine
- Additional clarification is needed from the user via follow-up questions
This intelligent triage ensures each query takes the optimal path to resolution rather than forcing all user messages through the same processing pipeline.

3. Dual processing paths
Based on the recognized intent, queries then follow one of two paths:
Process automation (Decision Engine)
When a query maps to a specific business process that needs better control over how it’s executed—like processing returns or managing account changes—our Decision Engine takes over. This specialized automation engine:
- Talks directly with the user to gather necessary information
- Enriches user context with relevant data points from APIs
- Delegates decision making to code or API
- Delivers a resolution or confirms process completion
Reasoning Engine
For everything else that requires knowledge synthesis, information from the product catalog, and reasoning, the query enters our Reasoning Engine. This advanced processing environment:
- Searches our knowledge base for relevant information
- Searches product catalog for relevant products
- Incorporates observations collected so far
- Understands if the question is outside of their context and then takes action
- Determines if follow-up questions are needed for clarification
- Makes a decisive assessment of whether it can provide an accurate answer
- Determines one of the possible outcomes:
- Provide accurate answer based on the context
- Follow-up with additional questions
- Transfer to an agent if the context it’s collected isn’t sufficient
When the Reasoning Engine can confidently answer the query, it generates a response that's both accurate and contextually appropriate. If it can’t answer confidently, the system routes the conversation to a human agent with all relevant context preserved.
4. Continuous learning
Throughout this flow, every decision point and pathway generates valuable data. We collect these signals and use them to improve the overall architecture and behavior. But we also make the data available to our customers, so that they can understand why the AI Agent chose one path or decision over another—and then can optimize or adjust as needed.
The foundations of Zowie’s AI Agent
Omnichannel integrations
Zowie's AI Agent operates as a unified intelligence hub across multiple channels:
The same AI brain powers responses across all these touchpoints, maintaining consistent knowledge and reasoning capabilities regardless of channel.

Adaptive interaction layer
Where most systems simply format messages differently by channel, our adaptive interaction layer preserves the integrity and quality of AI-generated responses across dramatically different communication environments.
This specialized interface performs real-time, channel-specific transformations:
When one of your end users reaches out via WhatsApp about product documentation, our AI Agent delivers a concise preview and link to the documentation. That same query through a voice interface triggers our adaptive interaction layer to extract key information, provide a short verbal summary, and ask if there are any follow-up questions.
Most importantly, our adaptive interaction layer maintains awareness of each channel's capabilities:
- It never attempts to send unsupported content types
- When advanced interaction types aren't available, it chooses simpler alternatives
- For channels with strict limitations like voice, it can take an entirely different approach
Without this sophisticated layer, even the most advanced AI would only succeed on one channel, but fail on others. With it, we deliver seamless intelligence that meets users wherever they are, however they choose to communicate.
Context enrichment
Context enrichment is like cognitive fuel inside Zowie's AI architecture. Without robust contextual understanding, any LLM will hallucinate. We've built a multi-layered context infrastructure to make sure that our AI Agent has access to the information it needs to respond correctly.
Our context enrichment system balances comprehensive understanding with computational efficiency—giving our AI Agent the foundation to deliver personalized, effective, and high-performing customer service.
Three tiers of context storage
Behind the scenes, we've implemented a specialized data structure for lightning-fast retrieval during real-time conversations. Our hybrid storage approach handles both in-memory processing for recent interactions as well as persistent storage for historical data. Each property is precisely tagged with temporal markers and semantic identifiers so that context can be assembled instantly, as and when it’s needed.
- Transformed details are available to the LLM: This is where raw data becomes meaningful. Before context ever reaches the LLM, it passes through a transformation pipeline. This processes context elements so that they’re ready for the LLM to use. For example, the pipeline:
- Normalizes inconsistent data formats into clean, standardized structures
- Enriches raw inputs with necessary metadata to explain the structure
- Prioritizes context elements by their actual relevance to the conversation
- Filters for the data that the LLM is allowed to see
- Structures information into LLM-optimized representations
Instead of a user’s raw purchase history from API, the LLM receives well-structured inputs.
- Short-term internal storage at the interaction level: Our interaction storage uses a dynamic state machine instead of basic session variables. This precisely tracks:
- Conversation progress markers that know exactly where users are in various resolution paths
- Entity references pinpointing specific objects being discussed
- Temporary preferences that apply only to the current interaction
- Long-term internal storage at the user level: Storage at this level functions as a comprehensive user profile that grows over time. It includes:
- Cross-channel identity resolution that delivers a unified user experience regardless of how they reach out
- Longitudinal insights that continuously deepen our understanding of user needs
- Compliance and privacy settings that honor user-specific data boundaries
With every new channel that our customers add, this layer becomes increasingly comprehensive.
Intent recognition
Understanding what users actually want—their true intent—remains one of the most fundamental challenges for effective AI agents. At Zowie, our three-step approach to gathering intents lets us balance efficiency with accuracy. We leverage different technologies in each step to make sure that the AI Agent is on the right track, without sacrificing speed.
Step 1. Gather all relevant intents
The first step employs a vector database approach similar to that used in knowledge-based search systems. At its core, this method works by transforming sentences into numerical vectors and comparing how similar they are to each other.
If a customer wants certain user queries to trigger process automations, then each AI Agent needs to have its own set of defined custom intents. You don’t need to list out every last possible intent—only the ones that map onto specific processes. For example, one agent will need to only recognize an intent like "what is my order status" while another might have both "order status" and "subscription status" intents because they offer both services.
For each intent, we ask our customers to provide between 20 to 100 reference phrases: semantic examples of how their users have previously expressed this particular need. The more diverse these reference phrases are, the better, as this enables the system to catch more nuanced variations of the same intent.
When a user query enters the system, it's converted to a vector and compared against these reference phrases. If our system finds matches primarily from a single intent category (e.g., "order status"), the intent is clear. However, this first step often returns multiple possible intents. When that happens, we go on to the second step.
Step 2. Use semantic descriptions for LLM disambiguation
If the first step yields multiple potential intents, we move to a disambiguation phase.
In this phase, we take the original query and the possible intents to an LLM and ask it to weigh in. The key piece that the LLM relies on here are semantic descriptions: detailed definitions in plain language of what each intent actually means in context.
We ask our customers to provide these semantic descriptions as part of the set-up for their AI Agent. The prompt for a semantic description would be something like, "Please describe what it means to check your order status or your subscription status." You might respond with: “If a customer wants to check their order status, they might want to know when the package will come or why it hasn’t been delivered.” These descriptions go beyond simple labels, providing rich contextual information about what each intent encompasses. Armed with these descriptions and the original user query, the LLM can often resolve the ambiguity, determining which intent most accurately matches the user's request.
Step 3. Follow up with the user for clarification
If even the LLM can’t confidently disambiguate between potential intents—maybe because the user's query doesn’t include enough specific detail—we proceed to the third step and clarify directly with the user.
This is exactly what it sounds like: the AI Agent asks the user to confirm the correct intent. For example, it might ask "Do you mean order or do you mean subscription?"
This follow-up leverages the same semantic descriptions to frame the question in user-friendly terms, rather than exposing the internal intent classification system. Our goal is to resolve what the intent is as quickly and smoothly as possible, while still arriving at the right answer.
Process automation with Zowie’s Decision Engine
All of the context and clarity is important, but in order for an AI Agent to be a transformative business tool, it has to be able to actually make something happen.
That’s exactly what Zowie’s Decision Engine does. It’s a key component of helping our customers to reduce their operating costs, boost revenue, and make life easy for their own customers. If the AI Agent identifies an intent that’s connected to a specific process, the Decision Engine starts running automatically to help get things done.
To illustrate: say a user wants to cancel their subscription. Using our three-step intent recognition, Zowie’s AI Agent has confirmed the intent behind the user’s query. This intent is linked to a predefined cancellation process. The AI Agent will keep conversing naturally with the user, while the Decision Engine kicks in behind the scenes, moving through each step of the process as needed:
- Collect the data needed to authorize the cancellation (e.g. order number, email, phone number) and confirm that it’s correct.
- Check the user’s status and eligibility for cancellation.
- Offer a discount or other incentive to avoid the cancellation.
- Proceed with the cancellation and send confirmation.
We’ve focused on core aspects that set Zowie’s Decision Engine apart:
Smart data gathering
The Decision Engine makes sure that the user experience isn’t rigid, clunky, or scripted. Our customers can use simple instructions in plain language to direct the AI Agent, and it will handle the rest. The AI Agent can guide users through a conversation that actually feels like a conversation, because it’s smart enough to understand typos and weird phrasing or help find the information without breaking the flow.
Accurate decision making
Generative AI is the right tool for the conversational component, but the Decision Engine is responsible for what actually happens. Thanks to clear, deterministic logic, the Decision Engine makes sure that our AI Agent doesn’t hallucinate–it follows the rules and processes that our customers set for their business.
Advanced process control
Zowie’s Decision Engine also includes a full JavaScript environment for automating complex, real-world business processes. It can connect to multiple systems at once, run workflows, apply logic, and transform data. This opens up even more new possibilities for what automation can do.
Knowledge base
Across our architecture, we’re always aiming to be both comprehensive and flexible. In terms of the knowledge base, this means ensuring that our AI Agent has access to the information it needs when it needs it. To achieve this, our knowledge base structure has several key features:
Integration with external systems
We've built robust integration pathways that let our customers seamlessly connect their existing tech stack. With these integrations, our AI Agent always has access to the most up-to-date information without requiring manual updates. We can pull in data from:
Ability to override
Sometimes, even the most comprehensive knowledge sources need to be adjusted for AI Agent to perform well. Our system includes flexible versioning so that our customers can:
- Quickly update specific pieces of information
- Create temporary rules for seasonal promotions or special circumstances
- Define priority hierarchies for conflicting information
- Implement immediate corrections when needed
Knowledge segmentation
Different user segments often need different information. Our integration allows for sophisticated knowledge segmentation based on various parameters:
This segmentation ensures that users receive only the most relevant information for their specific context, improving both the accuracy and the personalization of responses.
Retrieval Augmented Generation (RAG)
Despite how powerful they are, LLMs do have some significant limitations that can sometimes impact their effectiveness. For example:
- They may use non-authoritative sources about your company
- Their knowledge is limited to the time when their training dataset was collected
- They lack specific knowledge about your company's unique processes and policies
- Their decision-making can be opaque, making it difficult to understand why they respond in certain ways
While fine-tuning LLMs on company-specific content might seem like a solution, it introduces substantial cost, time overhead, and huge hallucination risks. This is where RAG (Retrieval Augmented Generation) comes in.
What is RAG?
At its core, RAG is a method to enhance LLM responses with relevant, up-to-date knowledge. The name itself breaks down the process:
This approach ensures that updating the model's knowledge is faster and more cost-effective than retraining or fine-tuning.

Why we’re using RAG
Our RAG implementation has several main advantages:
- Fewer hallucinations: The LLM can focus on rephrasing knowledge rather than generating it from scratch
- Up-to-date information: Knowledge can be updated instantly without model retraining
- Transparency: Responses are grounded in specific, identifiable sources
- Cost-efficiency: We only process relevant knowledge chunks, not entire knowledge bases
- Customization: Each client gets responses based on their specific knowledge, not generic information
By implementing RAG, we've created a system that combines the linguistic capabilities of LLMs with the accuracy and specificity of a curated knowledge base, for more natural and reliable responses.
How we’ve built RAG into Zowie’s architecture
For RAG to work effectively, you first need a place to store the information that will be relevant to the kinds of queries the LLM will receive. The success of RAG hinges on curating the knowledge repository that feeds the whole process:
- Ingestion pipeline: We preprocess data into textual formats suitable for LLM consumption. Documents are split into optimal chunks to reduce processing costs and improve relevance.
- Intelligent storage: Processed knowledge is stored in a specialized document store/retriever. We use a hybrid approach combining vector databases for semantic similarity and keyword search for specific terms, such as error codes or product names. This ensures we can find relevant information regardless of how it's referenced.
- Contextual retrieval: When a user asks a question, we optionally rewrite it to optimize for document retrieval. The system identifies and retrieves the most relevant knowledge pieces. We carefully filter results to maintain optimal context window usage, balancing comprehensiveness with efficiency.
- Enhanced response generation: The LLM answers the user's question based specifically on the retrieved documents. This produces responses that are shorter, more tailored, and grounded in authoritative sources. When appropriate, we can also provide source references to users for transparency.
What’s ahead at Zowie
We’re building Zowie for a world where technology and customer expectations both evolve faster than ever—and our AI architecture is designed to set the standard, not just keep pace. Every decision we make is grounded in the real problems our customers face, and Zowie is purpose-built for solving those problems and staying ahead of new ones. We don’t just adapt to change—we lead it.

.avif)